安装
官网下载
http://ffmpeg.org/

选择需要的版本

在这个网址下载ffmpeg,https://github.com/BtbN/FFmpeg-Builds/releases

将解压后得到的以下几个文件放置在E:\FFmpeg下

环境变量
此电脑--属性--高级系统设置--环境变量
在系统变量(也就是下面那一半)处找到新建,按如下所示的方法填写

再将%FFMPEG_HOME%以及%FFMPEG_HOME%\bin写入系统变量的Path中
然后一路确定即可
验证
win+R,cmd
输入ffmpeg -version

ffmpeg的使用
对于我将B站PC端缓存的音频mp4和视频mp4文件合并的需求,需要用到的命令为:
ffmpeg.exe -i audio1.mp4 -i video.mp4 -acodec copy -vcodec copy output.mp4
可以把mp4的文件设置成绝对路径,这样就可以转换指定路径的文件以及保存到指定路径了,比如这样:
ffmpeg.exe -i "E:\哔哩哔哩视频\ss27993\77413703\1\audio1.mp4" -i "E:\哔哩哔哩视频\ss27993\77413703\1\video.mp4" -acodec copy -vcodec copy "E:\B站导出视频\Dr.STONE石纪元\第22话宝物.mp4
通过PC端缓存的未合并的视频和音频,全都是命名为video.mp4和audio.mp4
PS:有些兄弟是导出的手机端缓存的视频和音频,是m4s格式的,方法也一样
但光有这条命令还不够,需要自己手动一个个操作,太麻烦了
因此我还需要使用Python来自动帮我完成工作
Python实现自动处理
虽然Python可以实现自动化,减少时间的浪费,但最快的还是以后记得缓存时勾选自动合并

文件结构
PC端缓存的视频保存的文件结构有很多种,我只是根据我碰到的情况写的,但大同小异,修改起来也不麻烦,只是再加个if和else罢了
番剧缓存结构
缓存的番剧是这种结构:

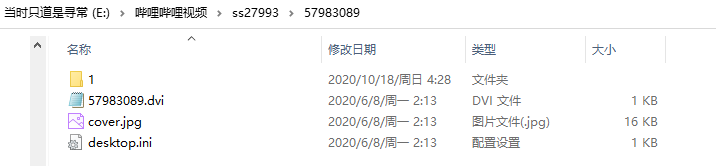

上面举的例子是Dr.stone石纪元,我缓存的鬼灭之刃也是如此
特点是在一个以视频ID号名称的文件夹(ss27993)后,跟着许多子文件夹(57983089等),然后在这些子文件夹中又有一个或多个子文件夹(比如1),然后缓存的视频保存在这个文件夹里,里面有一个info文件(就是json格式),还有audio1.mp4和video.mp4。
PS:
还有一个xml文件,是弹幕信息,暂时我不知道怎么处理

常规缓存结构
除了番剧,一般的视频缓存的结构是这样的

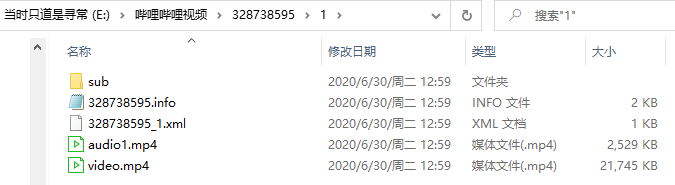
不难看出,这比番剧要少一个层级
文件信息
文件信息主要由info文件和dvi文件来记录
这两种文件都可以直接以json文件来处理,也就是,首先open函数打开文件,然后用json.load转成字典。。。
然后我还发现了一个特点是,视频和音频所在的目录下是info文件,而它的上一层目录下是dvi文件
虽然文件格式基本是一致的,但是里面的键-值关系却不一致,单集视频的名称在番剧中对应的是键Description,在其他视频中对应的是PartName
视频总的名称保存在外层的目录下的info文件或dvi文件中,番剧中对应的键是SeasonTitle,在其他视频中对应的是Title

具体问题具体分析,首先由于我实践得较少,这样的总结不一定对,然后以后也许也会有新的格式、新的变化
代码
具体代码
以下是我的Python代码,你可以先试试能不能用,用不了的话,可以在理解的基础上修改。理解不了的话可以看我的后面的解释,以及代码中的注释,对于运行过程中一些变量的值,我都把它放在注释中了,方便你理解。
# -*- coding = utf-8 -*-
# @time:2020/10/17/017 23:09
# Author:cyx
# @File:main.py.py
# @Software:PyCharm
# 从.info文件中获得了Title信息,但是如果其中有某些特殊字符,保存时可能出现问题
def get_correct_title(title):
error_set = ['/', '\\', ':', '*', '"', '|', '<', '>', '\b', ' ', '.']
correct_title = title
# print(title)
for c in correct_title:
if c in error_set:
correct_title = correct_title.replace(c, '')
return correct_title
def popen(cmd):
# https://blog.csdn.net/qq_41451161/article/details/82901235
try:
popen = subprocess.Popen(cmd, stdout=subprocess.PIPE)
popen.wait()
lines = popen.stdout.readlines()
return [line.decode('gbk') for line in lines]
except BaseException as e:
return -1
if __name__ == '__main__':
import os
import json
import subprocess
# ffmpeg -i video.m4s -i audio.m4s -c:v copy -c:a aac -strict experimental output.mp4
# ffmpeg.exe -i audio1.mp4 -i video.mp4 -acodec copy -vcodec copy output.mp4
AVhao = input("请输入视频AV号:")
superPath = "E:\\哔哩哔哩视频" + "\\" + AVhao
partDirs = [] # 保存每P视频所在的文件夹路径
paths = os.listdir(superPath) # 获取当前路径下所有的文件(包括文件夹)名称
# paths = ['8','9']
# 有时候,会莫名其妙的少了几个视频,可以通过重载来重新加载缺失的视频
# print(paths)
# paths
# ['27993.info', '57983089', '58612211', '59811008', '60862133', '61898240', '62925012', '64005445', '65020725', '66013155', '66808912', '67587875', '68398229', '69175748', '70021307', '70873680', '71617211', '73379440', '74051851', '74974157', '75746600', '76619409', '77413703', '78266594', '79070874', 'cover.jpg', 'desktop.ini']
# 获取每P视频所在的文件夹路径
savePos = ''
seq = []
# 鉴于有些up主命名时毫无规律,导出后无法正常排序,只能手动排序了
# 根据AV号名文件夹下的子文件夹的名称进行排序,但是番剧的话不是这样排序,不过番剧单集的名称很规范,不需要这样
for p in paths:
if '.' not in p:
seq.append(p)
if 'info' in p:
# print(p)
# p:
# 27993.info
info = superPath + "\\" + p
with open(info, 'r', encoding='utf-8') as load_f:
load_dict = json.load(load_f)
projectTitle = load_dict['SeasonTitle']
projectTitle = get_correct_title(projectTitle)
savePos = 'E:\\B站导出视频\\' + projectTitle
print('savePos: ', savePos)
if 'dvi' in p:
# print(p)
# P:
# 328738595.dvi
dvi = superPath + "\\" + p
with open(dvi, 'r', encoding='utf-8') as load_f:
load_dict = json.load(load_f)
projectTitle = load_dict['Title']
projectTitle = get_correct_title(projectTitle)
savePos = 'E:\\B站导出视频\\' + projectTitle
print('savePos: ', savePos)
# 防止文件存在时再次生成该文件夹出现错误
try:
os.mkdir(savePos)
break
except:
pass
subDir = superPath + "\\" + p
if os.path.isdir(subDir):
# print(subDir)
# 所有子文件夹的路径保存在partDirs中
partDirs.append(subDir)
# print("partDirs: ",partDirs)
# partDirs: ['E:\\哔哩哔哩视频\\ss27993\\57983089', 'E:\\哔哩哔哩视频\\ss27993\\58612211', 'E:\\哔哩哔哩视频\\ss27993\\59811008', 'E:\\哔哩哔哩视频\\ss27993\\60862133', 'E:\\哔哩哔哩视频\\ss27993\\61898240', 'E:\\哔哩哔哩视频\\ss27993\\62925012', 'E:\\哔哩哔哩视频\\ss27993\\64005445', 'E:\\哔哩哔哩视频\\ss27993\\65020725', 'E:\\哔哩哔哩视频\\ss27993\\66013155', 'E:\\哔哩哔哩视频\\ss27993\\66808912', 'E:\\哔哩哔哩视频\\ss27993\\67587875', 'E:\\哔哩哔哩视频\\ss27993\\68398229', 'E:\\哔哩哔哩视频\\ss27993\\69175748', 'E:\\哔哩哔哩视频\\ss27993\\70021307', 'E:\\哔哩哔哩视频\\ss27993\\70873680', 'E:\\哔哩哔哩视频\\ss27993\\71617211', 'E:\\哔哩哔哩视频\\ss27993\\73379440', 'E:\\哔哩哔哩视频\\ss27993\\74051851', 'E:\\哔哩哔哩视频\\ss27993\\74974157', 'E:\\哔哩哔哩视频\\ss27993\\75746600', 'E:\\哔哩哔哩视频\\ss27993\\76619409', 'E:\\哔哩哔哩视频\\ss27993\\77413703', 'E:\\哔哩哔哩视频\\ss27993\\78266594', 'E:\\哔哩哔哩视频\\ss27993\\79070874']
videoPos = ''
i = 0
for p in partDirs:
# print(p)
# 列出子文件夹中的所有文件
sublist = os.listdir(p)
# 检查info文件是否在当前子文件夹中
for file in sublist:
# print(file)
# file:
# 1
# 57983089.
# dvi
# cover.jpg
# desktop.ini
if 'info' in file:
infoPos = p + "\\" + file
videoPos = p
else:
subsubDir = p + "\\" + file
if os.path.isdir(subsubDir):
# print(subsubDir)
# subsubDir: E:\哔哩哔哩视频\ss27993\57983089\1
subsubList = os.listdir(subsubDir)
for subsubFile in subsubList:
if 'info' in subsubFile:
infoPos = subsubDir + "\\" + subsubFile
videoPos = subsubDir
break
with open(infoPos, 'r', encoding='utf-8') as load_f:
load_dict = json.load(load_f)
if 'ss' in AVhao:
videoTitle = load_dict['Description']
else:
videoTitle = load_dict['PartName']
videoTitle = get_correct_title(videoTitle)
print('videoTitle: ', videoTitle)
videoDir = videoPos + "\\" + 'video.mp4'
audioDir = videoPos + "\\" + 'audio1.mp4'
# print('videoDir: ', videoDir)
# print('audioDir: ', audioDir)
# videoDir: E:\哔哩哔哩视频\ss27993\74051851\1\video.mp4
# audioDir: E:\哔哩哔哩视频\ss27993\74051851\1\audio1.mp4
if 'ss' in AVhao:
outDir = savePos + "\\" + videoTitle + '.mp4'
else:
outDir = savePos + "\\" + seq[i] + '_' + videoTitle + '.mp4'
i += 1
# 对于那些命名很规范的视频,可以不用自己再排序,进行一下重载,不规范的视频再把这句注释掉就好
outDir = savePos + "\\" + videoTitle + '.mp4'
# command = 'cd ' + superPath + '\\64 && ' # && 多名命令
# command = 'cd ' + 'E:\\ProgramFiles\\ffmpeg' + ' && '
command = 'E:\\FFmpeg\\bin\\ffmpeg.exe -i ' + '"' + audioDir + '"' ' -i ' + '"' + videoDir + '"'+ ' -acodec copy -vcodec copy ' + '"' + outDir + '"'
# print("保存地址",outDir)
# 保存地址 E:\B站导出视频\[Lynda视频]音频录制录音技巧教程(中英双语字幕)全集130课时AudioRecordingTechniques混音录音棚音乐工作室歌曲调音\98录制独奏萨克斯演奏技巧二.mp4
# print(command)
# command = 'E:\\FFmpeg\\bin\\ffmpeg.exe -i "E:\哔哩哔哩视频\ss27993\77413703\1\audio1.mp4" -i "E:\哔哩哔哩视频\ss27993\77413703\1\video.mp4" -acodec copy -vcodec copy "E:\B站导出视频\Dr.STONE石纪元\第22话宝物.mp4'
# os.system(command)
popen(command)
# ffmpeg.exe -i audio1.mp4 -i video.mp4 -acodec copy -vcodec copy output.mp4
break
代码说明
如你所见我的编程水平不高,模块化做的很差,不便于理解,所以有必要进行说明。
直接从main开始看起吧。
AVhao = input("请输入视频AV号:")
superPath = "E:\\哔哩哔哩视频" + "\\" + AVhao
partDirs = [] # 保存每P视频所在的文件夹路径
paths = os.listdir(superPath) # 获取当前路径下所有的文件(包括文件夹)名称
首先是用input接收AV号或BV号的输入,放入AVhao变量中。
然后用superPath变量存放你需要合并的视频的根目录。比如我在B站缓存的所有视频存放在E:\哔哩哔哩视频下,注意程序中要有两条\,然后superPath就是E:\哔哩哔哩视频\AVhao。
os.listdir(),括号中的参数必须是一个真实的路径,这个函数可以得到这个路径下所有的文件和文件夹的名称。
我用paths来存放E:\哔哩哔哩视频\AVhao路径下所有的文件名称和文件夹名称。
为了防止我的表达能力有限带来的理解上的不便,你可以看图,paths对应的是下图中的内容:
这个变量的类型是列表,所以可以用for循环来遍历。
savePos = ''
seq = []
for p in paths:
if '.' not in p:
seq.append(p)
if 'info' in p:
# print(p)
# p:
# 27993.info
info = superPath + "\\" + p
with open(info, 'r', encoding='utf-8') as load_f:
load_dict = json.load(load_f)
projectTitle = load_dict['SeasonTitle']
projectTitle = get_correct_title(projectTitle)
savePos = 'E:\\B站导出视频\\' + projectTitle
print('savePos: ', savePos)
if 'dvi' in p:
# print(p)
# P:
# 328738595.dvi
dvi = superPath + "\\" + p
with open(dvi, 'r', encoding='utf-8') as load_f:
load_dict = json.load(load_f)
projectTitle = load_dict['Title']
projectTitle = get_correct_title(projectTitle)
savePos = 'E:\\B站导出视频\\' + projectTitle
print('savePos: ', savePos)
# 防止文件存在时再次生成该文件夹出现错误
try:
os.mkdir(savePos)
break
except:
pass
subDir = superPath + "\\" + p
if os.path.isdir(subDir):
# print(subDir)
# 所有子文件夹的路径保存在partDirs中
partDirs.append(subDir)
我设置了一个savePos变量,用来表示合并后的视频保存的位置,因为我希望将视频保存在一个我自己指定的文件夹下,同时这个文件夹的名称是这个视频的名称,比如Dr.stone石纪元。
因为想自动化操作,所以我通过缓存文件夹中的info文件和dvi文件来找到视频的名称。
使用open函数打开这两个文件中的一个,因为不确定文件结构是什么样的,所以我用了两个if语句。
然后再用json.load函数将其加载为字典,并根据对应的键读取对应的值,从而可以拼接处对应的保存地址savePos。
由于创建已经存在的同名文件夹会发生错误,为避免这种可能,我将创建目录的操作放在了try语句下。
创建目录用的是os.mkdir()函数,括号中是一个绝对路径。
然后我用subDir来表示子文件夹的名称,注意!是子文件夹,而不是文件。
我用os.path.isdir(subDir)来进行判断,如果是文件夹而不是文件的话,就加到partDirs列表中,partDirs.append(subDir)
这个列表中的每个元素都是一个子文件夹的绝对路径,比如:E:\哔哩哔哩视频\ss27993\57983089
而这个名为seq的显得很突兀,这个其实我也是后来加的,这个列表的作用在于记录当前子文件夹的名称,也就是在AVhao文件夹的下一层,如果不是番剧的话,应当有许多个文件夹分别是1、2、3等等,这些其实对应的是播放列表中的顺序。

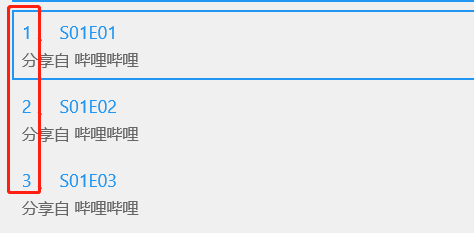
而之所以使用if '.' not in p,因为这一层的文件夹全都是用来表示播放顺序的,因此不存在后缀名,从而也就没有“.”。
videoPos = ''
i = 0
for p in partDirs:
# print(p)
# 列出子文件夹中的所有文件
sublist = os.listdir(p)
# 检查info文件是否在当前子文件夹中
for file in sublist:
# print(file)
# file:
# 1
# 57983089.
# dvi
# cover.jpg
# desktop.ini
if 'info' in file:
infoPos = p + "\\" + file
videoPos = p
else:
subsubDir = p + "\\" + file
if os.path.isdir(subsubDir):
# print(subsubDir)
# subsubDir: E:\哔哩哔哩视频\ss27993\57983089\1
subsubList = os.listdir(subsubDir)
for subsubFile in subsubList:
if 'info' in subsubFile:
infoPos = subsubDir + "\\" + subsubFile
videoPos = subsubDir
break
with open(infoPos, 'r', encoding='utf-8') as load_f:
load_dict = json.load(load_f)
if 'ss' in AVhao:
videoTitle = load_dict['Description']
else:
videoTitle = load_dict['PartName']
videoTitle = get_correct_title(videoTitle)
print('videoTitle: ', videoTitle)
videoDir = videoPos + "\\" + 'video.mp4'
audioDir = videoPos + "\\" + 'audio1.mp4'
# print('videoDir: ', videoDir)
# print('audioDir: ', audioDir)
# videoDir: E:\哔哩哔哩视频\ss27993\74051851\1\video.mp4
# audioDir: E:\哔哩哔哩视频\ss27993\74051851\1\audio1.mp4
if 'ss' in AVhao:
outDir = savePos + "\\" + videoTitle + '.mp4'
else:
outDir = savePos + "\\" + seq[i] + '_' + videoTitle + '.mp4'
i += 1
# 对于那些命名很规范的视频,可以不用自己再排序,进行一下重载,不规范的视频再把这句注释掉就好
outDir = savePos + "\\" + videoTitle + '.mp4'
# command = 'cd ' + superPath + '\\64 && ' # && 多名命令
# command = 'cd ' + 'E:\\ProgramFiles\\ffmpeg' + ' && '
command = 'E:\\FFmpeg\\bin\\ffmpeg.exe -i ' + '"' + audioDir + '"' ' -i ' + '"' + videoDir + '"'+ ' -acodec copy -vcodec copy ' + '"' + outDir + '"'
# print("保存地址",outDir)
# 保存地址 E:\B站导出视频\[Lynda视频]音频录制录音技巧教程(中英双语字幕)全集130课时AudioRecordingTechniques混音录音棚音乐工作室歌曲调音\98录制独奏萨克斯演奏技巧二.mp4
# print(command)
# command = 'E:\\FFmpeg\\bin\\ffmpeg.exe -i "E:\哔哩哔哩视频\ss27993\77413703\1\audio1.mp4" -i "E:\哔哩哔哩视频\ss27993\77413703\1\video.mp4" -acodec copy -vcodec copy "E:\B站导出视频\Dr.STONE石纪元\第22话宝物.mp4'
# os.system(command)
popen(command)
# ffmpeg.exe -i audio1.mp4 -i video.mp4 -acodec copy -vcodec copy output.mp4
break
这一部分是我用来实现合并特定路径的视频和音频,并最终导出到指定目录的。
videoPos是待合并的视频的路径,音频文件也在这一目录下。
for p in partDirs:,在这个for循环中遍历的是partDirs列表,这个列表由前面的步骤得到,其中的每个元素都是一个路径。
接下来的这个if-else是用来区别番剧和普通视频合集的,因为它们有不同的目录结构。
infoPos用来记录包含单集视频名称的info文件的路径,然后用open函数打开这个info文件,根据AVhao中是否有ss,判断是否是番剧,如果有ss,则表明是番剧,对应的视频名称为Description键对应的值。否则的话,对应的视频名称为PartName键对应的值,但是如果是要保存为文件的话,当然不能直接以这个名称命名,否则极有可能发生错误,因此我用了一个get_correct_title函数来对标题进行重载,以确保格式正确。
videoDir和audioDir分别是待合并的视频和音频的绝对路径。
然后我根据AVhao中是否有ss,来判断是否是番剧。因为番剧的单集视频名称通常会有序号,所以我可以将输出视频的保存路径设置为保存目录加视频名.mp4。
许多up主的视频名称没有体现视频的先后顺序,这样带来的问题是导出后顺序播放时产生跳集现象。因此我用seq加下划线的方式来为视频排序。比如“1_简介.mp4”。
而对于视频名称本身有排序的情况1_1简介.mp4,这样有些奇怪,所以我们碰到这种情况时,可以直接在下面添加一个outDir = savePos + "\\" + videoTitle + '.mp4',其他情况不用时注释掉就好。
最后是用Python程序执行Dos命令,我将命令设为command变量,通过for循环,会自动生成不同的命令,然后执行命令行有两种方法,一种是导入os库,使用os.system(command),另一种是我在https://blog.csdn.net/qq_41451161/article/details/82901235借用的popen函数,这个也可以用,但需要导入subprocess库。
使用命令行上,有两个比较坑的地方,一是前面必须给出ffmpeg.exe的绝对路径,也就是E:\FFmpeg\bin\ffmpeg.exe,在Python中用是这样的,但直接在命令行中,只要输入ffmpeg.exe即可(前提是你设置好了环境变量)。第二个坑是,command赋值时,一定给路径加上引号,否则的话识别命令时会发生错误。
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件! 如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
P70系列延期,华为新旗舰将在下月发布
3月20日消息,近期博主@数码闲聊站 透露,原定三月份发布的华为新旗舰P70系列延期发布,预计4月份上市。
而博主@定焦数码 爆料,华为的P70系列在定位上已经超过了Mate60,成为了重要的旗舰系列之一。它肩负着重返影像领域顶尖的使命。那么这次P70会带来哪些令人惊艳的创新呢?
根据目前爆料的消息来看,华为P70系列将推出三个版本,其中P70和P70 Pro采用了三角形的摄像头模组设计,而P70 Art则采用了与上一代P60 Art相似的不规则形状设计。这样的外观是否好看见仁见智,但辨识度绝对拉满。
更新日志
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]