本文实例讲述了Python通过VGG16模型实现图像风格转换操作。分享给大家供大家参考,具体如下:
1、图像的风格转化
卷积网络每一层的激活值可以看作一个分类器,多个分类器组成了图像在这一层的抽象表示,而且层数越深,越抽象
内容特征:图片中存在的具体元素,图像输入到CNN后在某一层的激活值
风格特征:绘制图片元素的风格,各个内容之间的共性,图像在CNN网络某一层激活值之间的关联
风格转换:在一幅图片内容特征的基础上添加另一幅图片的风格特征从而生成一幅新的图片。在卷积模型训练中,通过输入固定的图片来调整网络的参数从而达到利用图片训练网络的目的。而在生成特定风格图片时,固定已有的网络参数不变,调整图片从而使图片向目标风格转化。在内容风格转换时,调整图像的像素值,使其向目标图片在卷积网络输出的内容特征靠拢。在风格特征计算时,通过多个神经元的输出两两之间作内积求和得到Gram矩阵,然后对G矩阵做差求均值得到风格的损失函数。

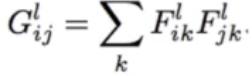
将内容损失函数和风格损失函数对应乘以权重再加起来就得到了总的损失函数,最后的生成图既有内容特征也有风格特征
2、通过Vgg16实现
2.1、预训练模型读取
通过预训练好的Vgg16模型来对图片进行风格转换,首先需要准备好vgg16的模型参数。链接: https://pan.baidu.com/s/1shw2M3Iv7UfGjn78dqFAkA 提取码: ejn8
通过numpy.load()导入并查看参数的内容:
import numpy as np
data=np.load('./vgg16_model.npy',allow_pickle=True,encoding='bytes')
# print(data.type())
data_dic=data.item()
# 查看网络层参数的键值
print(data_dic.keys())
打印键值如下,可以看到分别有不同的卷积和全连接层:
dict_keys([b'conv5_1', b'fc6', b'conv5_3', b'conv5_2', b'fc8', b'fc7', b'conv4_1', b'conv4_2', b'conv4_3', b'conv3_3', b'conv3_2', b'conv3_1', b'conv1_1', b'conv1_2', b'conv2_2', b'conv2_1'])
接着查看具体每层的参数,通过data_dic[key]可以获取到key对应层次的参数,例如可以看到卷积层1_1的权值w为3个3×3的卷积核,对应64个输出通道
# 查看卷积层1_1的参数w,b w,b=data_dic[b'conv1_1'] print(w.shape,b.shape) # (3, 3, 3, 64) (64,) # 查看全连接层的参数 w,b=data_dic[b'fc8'] print(w.shape,b.shape) # (4096, 1000) (1000,)
2.2、构建VGG网络
通过将已经训练好的参数填充到网络之中就可以搭建VGG网络了。
在类初始化函数中读取预训练模型文件中的参数到self.data_dic
首先构建卷积层,通过传入的各个卷积层name参数,读取模型中对应的卷积层参数并填充到网络中。例如读取第一个卷积层的权值和偏置值,传入name='conv1_1,则data_dic[name][0]可以得到权值weight,data_dic[name][1]得到偏置值bias。通过tf.constant构建常量,再执行卷积操作,加偏置项,经激活函数后输出。
接下来实现池化操作,由于池化不需要参数,所以直接对输入进行最大池化操作后输出即可
接着经过展开层,由于卷积池化后的数据是四维向量[batch_size,image_width,image_height,chanel],需要将最后三维展开,将最后三个维度相乘,通过tf.reshape()展开
最后需要把结果经过全连接层,它的实现和卷积层类似,读取权值和偏置参数后进行全连接操作后输出。
class VGGNet:
def __init__(self, data_dir):
data = np.load(data_dir, allow_pickle=True, encoding='bytes')
self.data_dic = data.item()
def conv_layer(self, x, name):
# 实现卷积操作
with tf.name_scope(name):
# 从模型文件中读取各卷积层的参数值
weight = tf.constant(self.data_dic[name][0], name='conv')
bias = tf.constant(self.data_dic[name][1], name='bias')
# 进行卷积操作
y = tf.nn.conv2d(x, weight, [1, 1, 1, 1], padding='SAME')
y = tf.nn.bias_add(y, bias)
return tf.nn.relu(y)
def pooling_layer(self, x, name):
# 实现池化操作
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name=name)
def flatten_layer(self, x, name):
# 实现展开层
with tf.name_scope(name):
# x_shape->[batch_size,image_width,image_height,chanel]
x_shape = x.get_shape().as_list()
dimension = 1
# 计算x的最后三个维度积
for d in x_shape[1:]:
dimension *= d
output = tf.reshape(x, [-1, dimension])
return output
def fc_layer(self, x, name, activation=tf.nn.relu):
# 实现全连接层
with tf.name_scope(name):
# 从模型文件中读取各全连接层的参数值
weight = tf.constant(self.data_dic[name][0], name='fc')
bias = tf.constant(self.data_dic[name][1], name='bias')
# 进行全连接操作
y = tf.matmul(x, weight)
y = tf.nn.bias_add(y, bias)
if activation==None:
return y
else:
return tf.nn.relu(y)
通过self.build()函数实现Vgg16网络的搭建.数据输入后首先需要进行归一化处理,将输入的RGB数据拆分为R、G、B三个通道,再将三个通道分别减去一个固定值,最后将三通道按B、G、R顺序重新拼接为一个新的数据。
接下来则是通过上面的构建函数来搭建VGG网络,依次将五层的卷积池化网络、展开层、三个全连接层的参数读入各层,并搭建起网络,最后经softmax输出
def build(self,x_rgb):
s_time=time.time()
# 归一化处理,在第四维上将输入的图片的三通道拆分
r,g,b=tf.split(x_rgb,[1,1,1],axis=3)
# 分别将三通道上减去特定值归一化后再按bgr顺序拼起来
VGG_MEAN = [103.939, 116.779, 123.68]
x_bgr=tf.concat(
[b-VGG_MEAN[0],
g-VGG_MEAN[1],
r-VGG_MEAN[2]],
axis=3
)
# 判别拼接起来的数据是否符合期望,符合再继续往下执行
assert x_bgr.get_shape()[1:]==[668,668,3]
# 构建各个卷积、池化、全连接等层
self.conv1_1=self.conv_layer(x_bgr,b'conv1_1')
self.conv1_2=self.conv_layer(self.conv1_1,b'conv1_2')
self.pool1=self.pooling_layer(self.conv1_2,b'pool1')
self.conv2_1=self.conv_layer(self.pool1,b'conv2_1')
self.conv2_2=self.conv_layer(self.conv2_1,b'conv2_2')
self.pool2=self.pooling_layer(self.conv2_2,b'pool2')
self.conv3_1=self.conv_layer(self.pool2,b'conv3_1')
self.conv3_2=self.conv_layer(self.conv3_1,b'conv3_2')
self.conv3_3=self.conv_layer(self.conv3_2,b'conv3_3')
self.pool3=self.pooling_layer(self.conv3_3,b'pool3')
self.conv4_1 = self.conv_layer(self.pool3, b'conv4_1')
self.conv4_2 = self.conv_layer(self.conv4_1, b'conv4_2')
self.conv4_3 = self.conv_layer(self.conv4_2, b'conv4_3')
self.pool4 = self.pooling_layer(self.conv4_3, b'pool4')
self.conv5_1 = self.conv_layer(self.pool4, b'conv5_1')
self.conv5_2 = self.conv_layer(self.conv5_1, b'conv5_2')
self.conv5_3 = self.conv_layer(self.conv5_2, b'conv5_3')
self.pool5 = self.pooling_layer(self.conv5_3, b'pool5')
self.flatten=self.flatten_layer(self.pool5,b'flatten')
self.fc6=self.fc_layer(self.flatten,b'fc6')
self.fc7 = self.fc_layer(self.fc6, b'fc7')
self.fc8 = self.fc_layer(self.fc7, b'fc8',activation=None)
self.prob=tf.nn.softmax(self.fc8,name='prob')
print('模型构建完成,用时%d秒'%(time.time()-s_time))
2.3、图像风格转换
首先需要定义网络的输入与输出。网络的输入是风格图像和内容图像,两张图象都是668×668的3通道图片。首先通过PIL库中的Image对象完成读入内容图像style_img和风格图像content_img,并将其转化为数组,定义对应的占位符style_in和content_in,在训练时将图片填入。
网络的输出是一张结果图片668×668的3通道,通过随机函数初始化一个结果图像的数组res_out。
利用上面定义的VGGNet类来创建图片对象,并完成build操作。
vgg16_dir = './data/vgg16_model.npy' style_img = './data/starry_night.jpg' content_img = './data/city_night.jpg' output_dir = './data' def read_image(img): img = Image.open(img) img_np = np.array(img) # 将图片转化为[668,668,3]数组 img_np = np.asarray([img_np], ) # 转化为[1,668,668,3]的数组 return img_np # 输入风格、内容图像数组 style_img = read_image(style_img) content_img = read_image(content_img) # 定义对应的输入图像的占位符 content_in = tf.placeholder(tf.float32, shape=[1, 668, 668, 3]) style_in = tf.placeholder(tf.float32, shape=[1, 668, 668, 3]) # 初始化输出的图像 initial_img = tf.truncated_normal((1, 668, 668, 3), mean=127.5, stddev=20) res_out = tf.Variable(initial_img) # 构建VGG网络对象 res_net = VGGNet(vgg16_dir) style_net = VGGNet(vgg16_dir) content_net = VGGNet(vgg16_dir) res_net.build(res_out) style_net.build(style_in) content_net.build(content_in)
接着需要定义损失函数loss。
对于内容损失,先选定内容风格图像和结果图像的卷积层,要相同,比如这里选取了卷积层1_1和2_1。然后这两个特征层的后三个通道求平方差,然后取均值,就是内容损失。
对于风格损失,首先需要对风格图像和结果图像的特征层求gram矩阵,然后对gram矩阵求平方差的均值。
最后按照系数比例将两个损失函数相加即可得到loss
# 计算损失,分别需要计算内容损失和风格损失 # 提取内容图像的内容特征 content_features = [ content_net.conv1_2, content_net.conv2_2 # content_net.conv2_2 ] # 对应结果图像提取相同层的内容特征 res_content = [ res_net.conv1_2, res_net.conv2_2 # res_net.conv2_2 ] # 计算内容损失 content_loss = tf.zeros(1, tf.float32) for c, r in zip(content_features, res_content): content_loss += tf.reduce_mean((c - r) ** 2, [1, 2, 3]) # 计算风格损失的gram矩阵 def gram_matrix(x): b, w, h, ch = x.get_shape().as_list() features = tf.reshape(x, [b, w * h, ch]) # 对features矩阵作内积,再除以一个常数 gram = tf.matmul(features, features, adjoint_a=True) / tf.constant(w * h * ch, tf.float32) return gram # 对风格图像提取特征 style_features = [ # style_net.conv1_2 style_net.conv4_3 ] style_gram = [gram_matrix(feature) for feature in style_features] # 提取结果图像对应层的风格特征 res_features = [ res_net.conv4_3 ] res_gram = [gram_matrix(feature) for feature in res_features] # 计算风格损失 style_loss = tf.zeros(1, tf.float32) for s, r in zip(style_gram, res_gram): style_loss += tf.reduce_mean((s - r) ** 2, [1, 2]) # 模型内容、风格特征的系数 k_content = 0.1 k_style = 500 # 按照系数将两个损失值相加 loss = k_content * content_loss + k_style * style_loss
接下来开始进行100轮的训练,打印并查看过程中的总损失、内容损失、风格损失值。并将每轮的生成结果图片输出到指定目录下
# 进行训练
learning_steps = 100
learning_rate = 10
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(learning_steps):
t_loss, c_loss, s_loss, _ = sess.run(
[loss, content_loss, style_loss, train_op],
feed_dict={content_in: content_img, style_in: style_img}
)
print('第%d轮训练,总损失:%.4f,内容损失:%.4f,风格损失:%.4f'
% (i + 1, t_loss[0], c_loss[0], s_loss[0]))
# 获取结果图像数组并保存
res_arr = res_out.eval(sess)[0]
res_arr = np.clip(res_arr, 0, 255) # 将结果数组中的值裁剪到0~255
res_arr = np.asarray(res_arr, np.uint8) # 将图片数组转化为uint8
img_path = os.path.join(output_dir, 'res_%d.jpg' % (i + 1))
# 图像数组转化为图片
res_img = Image.fromarray(res_arr)
res_img.save(img_path)
运行结果如下可以看到依次分别为内容图片、风格图片、训练12轮、46轮、100轮结果图片





更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数据结构与算法教程》、《Python加密解密算法与技巧总结》、《Python编码操作技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件! 如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
《魔兽世界》大逃杀!60人新游玩模式《强袭风暴》3月21日上线
暴雪近日发布了《魔兽世界》10.2.6 更新内容,新游玩模式《强袭风暴》即将于3月21 日在亚服上线,届时玩家将前往阿拉希高地展开一场 60 人大逃杀对战。
艾泽拉斯的冒险者已经征服了艾泽拉斯的大地及遥远的彼岸。他们在对抗世界上最致命的敌人时展现出过人的手腕,并且成功阻止终结宇宙等级的威胁。当他们在为即将于《魔兽世界》资料片《地心之战》中来袭的萨拉塔斯势力做战斗准备时,他们还需要在熟悉的阿拉希高地面对一个全新的敌人──那就是彼此。在《巨龙崛起》10.2.6 更新的《强袭风暴》中,玩家将会进入一个全新的海盗主题大逃杀式限时活动,其中包含极高的风险和史诗级的奖励。
《强袭风暴》不是普通的战场,作为一个独立于主游戏之外的活动,玩家可以用大逃杀的风格来体验《魔兽世界》,不分职业、不分装备(除了你在赛局中捡到的),光是技巧和战略的强弱之分就能决定出谁才是能坚持到最后的赢家。本次活动将会开放单人和双人模式,玩家在加入海盗主题的预赛大厅区域前,可以从强袭风暴角色画面新增好友。游玩游戏将可以累计名望轨迹,《巨龙崛起》和《魔兽世界:巫妖王之怒 经典版》的玩家都可以获得奖励。
更新日志
- 明达年度发烧碟MasterSuperiorAudiophile2021[DSF]
- 英文DJ 《致命的温柔》24K德国HD金碟DTS 2CD[WAV+分轨][1.7G]
- 张学友1997《不老的传说》宝丽金首版 [WAV+CUE][971M]
- 张韶涵2024 《不负韶华》开盘母带[低速原抓WAV+CUE][1.1G]
- lol全球总决赛lcs三号种子是谁 S14全球总决赛lcs三号种子队伍介绍
- lol全球总决赛lck三号种子是谁 S14全球总决赛lck三号种子队伍
- 群星.2005-三里屯音乐之男孩女孩的情人节【太合麦田】【WAV+CUE】
- 崔健.2005-给你一点颜色【东西音乐】【WAV+CUE】
- 南台湾小姑娘.1998-心爱,等一下【大旗】【WAV+CUE】
- 【新世纪】群星-美丽人生(CestLaVie)(6CD)[WAV+CUE]
- ProteanQuartet-Tempusomniavincit(2024)[24-WAV]
- SirEdwardElgarconductsElgar[FLAC+CUE]
- 田震《20世纪中华歌坛名人百集珍藏版》[WAV+CUE][1G]
- BEYOND《大地》24K金蝶限量编号[低速原抓WAV+CUE][986M]
- 陈奕迅《准备中 SACD》[日本限量版] [WAV+CUE][1.2G]